Autres conteneurs séquentiels
Vous allez maintenant manipuler les autres conteneurs séquentiels que la libraire propose.
Pour cet exercice, vous modifierez le fichier :
- chap-05/2-sequentials.cpp
La cible à compiler est c5-2-sequentials.
Tableaux de taille fixe
Pour créer des tableaux de taille fixe, il est bien entendu possible d’utiliser les tableaux primitifs. L’inconvénient, c’est qu’il faut penser à les initialiser, ce que tout le monde ne pense pas toujours à faire….
Du coup, pour pallier à ce problème, il est possible d’utiliser la classe std::array. Dans les paramètres de template, il faut préciser le type des éléments, comme pour vector, mais il faut également indiquer la taille du tableau :
std::array<int, 3> an_array_with_3_elements;
Lorsque vous fournissez une expression à un paramètre de template, il faut que le compilateur soit capable de calculer la valeur de cette expression au moment de la compilation.
Si vous essayez d’utiliser une variable pour indiquer la taille d’un std::array, vous aurez donc une erreur de compilation.
Dans quelle situation peut-on utiliser un std::array ?
Un des cas d’utilisation classique est lorsque l’on souhaite créer un tableau associatif indexé par des entiers de 0 à N.
Cela s’y prête d’autant plus lorsque l’indice est en réalité une enumération.
Pour définir et utiliser des enum en C++, c’est un peu plus simple qu’en C : il n’y a pas besoin de faire de typedef pour référencer l’enum par son nom.
Dans le code de base du fichier, vous pouvez trouver une énumération Fruit, contenant les valeurs Apricot, Cherry, Mango et Raspberry. Vous avez également une dernière valeur Fruit_Count, qui contient donc le nombre de valeurs de l’enum.
Définissez un array servant à indiquer pour chaque fruit possible le nom de ce fruit. Assignez ensuite dans chaque case la valeur appropriée.
C’est quoi l’intérêt d’utiliser un array, alors qu’on peut faire la même chose, et même plus, avec un vector ?
Une partie de la réponse est dans la question : en programmation, faire plus, c’est rarement synonyme de faire mieux…
Lorsqu’une classe permet de répondre exactement à un besoin, il vaut mieux utiliser cette classe là plutôt qu’en utiliser une autre qui répond aussi au besoin, mais vous permet en plus de faire le café, nettoyer les toilettes et détruire le monde. Pourquoi ? Tout simplement parce que moins il y a de code à devoir supporter, plus c’est simple de maintenir ses programmes et de les faire évoluer.
Une autre raison de préférer l’usage d’un array à un vector est de réduire le nombre d’allocations dynamiques du programme. En effet, contrairement aux vector, l’espace de stockage des array peut être placé sur la pile. C’est toujours intéressant de s’économiser des opérations coûteuses lorsqu’on en a la possibilité.
Listes chaînées
La librairie standard implémente les classes std::list et std::forward_list, qui représente respectivement des listes doublement et simplement chaînées.
L’intérêt des listes vis-à-vis des tableaux, c’est qu’il est possible d’insérer ou de supprimer des éléments en O(1). De nouvelles fonctions de modifications sont donc disponibles dans l’interface de la liste, comme merge (fusionner deux listes), splice (insérer une liste au milieu d’une autre), remove (retirer des éléments selon leur valeur) ou encore sort (trier la liste).
L’inconvénient, c’est qu’il n’est plus possible d’accéder à un élément depuis sa position en O(1). D’ailleurs, l’opérateur [] n’est pas disponible sur les listes de la STL.
Dans la fonction try_lists, quatres listes vides sont définies. Commencez par leur ajouter des valeurs (de la manière de votre choix).
Faites ensuite en sorte de regrouper l1 et l2 dans une même liste ordonnée. Faites de même avec l3 et l4.
Placez enfin le résultat du deuxième groupement en plein milieu du premier groupement.
Concrètement, que peut-on faire avec une list que l’on ne peut pas faire avec une forward_list ?
Dans une forward_list, on ne connaît que le début de la liste. Il faut donc la parcourir en entier si on veut accéder à la fin. Il n’est aussi pas possible de la parcourir à l’envers.
A part cela, les autres opérations sont disponibles avec la même complexité.
Pile ou File
Les derniers conteneurs que nous allons ici sont les piles std::stack et les files std::queue. Nous n’allons pas rappeler en détail ce que sont les piles ou les files, mais si vous avez tout oublier de vos cours d’algorithmique, sachez au moins que dans une pile, les insertions et suppressions sont effectuées en fin de conteneur, alors que dans une file, les suppressions s’effectuent en tête et les insertions en fin de conteneur.
Dans le cas de la STL, stack et queue ont la particularité d’être des adapteurs. Cela signifie que vous pouvez choisir l’implémentation que vous souhaitez utiliser en interne. La seule contrainte, c’est que la classe sous-jacente doit fournir certaines fonctions. Par exemple, dans le cas de la pile, on pourrait utiliser vector ou list, mais pas forward_list car elle ne définit pas push_back :
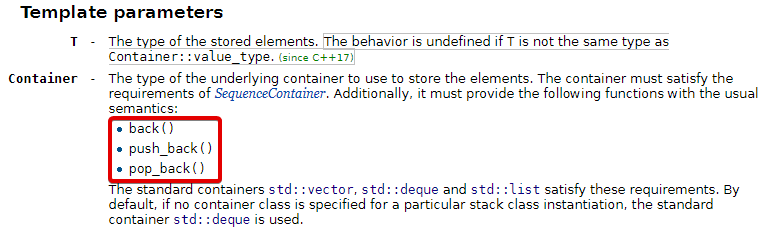
Sur l’image ci-dessus, on vous précise quel conteneur est utilisé par défaut si vous n’en spécifier aucun (c’est-à-dire si vous écrivez juste std::stack<int>, au lieu de std::stack<int, smtg>). De quelle classe s’agit-il ?
En cherchant un petit peu dans sa documentation, essayez de trouver une raison pour laquelle la librairie a décidé d’utiliser ce conteneur là par défaut.
Vous allez maintenant instancier une stack utilisant comme implémentation sous-jacente un vector<int>, plutôt qu’une deque. Pour cela, il suffit de spécifier le type de conteneur dans un second paramètre de template.
Faites en sorte que la stack contienne à la fin { 0, 1, 2 }.
Essayez maintenant de parcourir la stack via une boucle for pour l’afficher (pas foreach). Qu’est-ce qui pose problème ?
Retentez maintenant le parcours via une boucle foreach. Essayez de compiler, et déduisez-en le nom des fonctions attendues par le compilateur pour pouvoir parcourir un conteneur via une boucle foreach.